
The Scraping Architecture Blueprint: Why Mainstream Clouds Fail Massive Automation Frameworks
Web scraping, large-scale data aggregation, and continuous automation loops are the lifeblood of modern market intelligence, price comparison engines, and competitive analysis platforms. However, engineers and data strategists launching high-throughput extraction pipelines face a structural roadblock: the mainstream cloud hosting ecosystem.
Running high-concurrency browser automation frameworks (like Playwright, Puppeteer, or Selenium headless) on AWS, GCP, or DigitalOcean quickly hits a wall. Their centralized IPs are flagged by anti-bot systems like Cloudflare and Akamai, so heavy crawling soon encounters CAPTCHA, 403 errors, and IP blocks. Also, mainstream hosts may terminate accounts due to restrictive policies triggered by automated scraping.
To achieve maximum extraction velocity and prevent pipeline interruptions, operations must migrate to unmetered offshore servers. This technical guide breaks down the core architecture for deploying high-scale web scraping and data automation systems on offshorededicatedservers.com, detailing network routing setups, hardware specifications, and system optimization rules.
The Network Advantage: Bypassing IP Reputation and Cloud Bans
When scraping at scale, your single greatest asset is network diversity. Mainstream cloud vendors host millions of web assets alongside internal services. Because they assign IP addresses in easily identifiable, contiguous blocks (Autonomous System Numbers, or ASNs), anti-scraping firewalls can block thousands of scrapers at once simply by blacklisting a single AWS or GCP IP range.
[Mainstream Cloud ASN] ──(Highly Flagged Range)──> [Target Enterprise Firewall] ──> Instant Block / CAPTCHA
[Offshore Dedicated ASN] ──(Clean, Custom Routing)──> [Target Enterprise Firewall] ──> Clean HTTP 200 OK ResponseBy transitioning to specialized offshore servers, your automation infrastructure benefits from distinct network advantages:
- Residential and Clean Commercial ASN Blending: High-tier offshore facilities utilize custom routing tables that blend regional commercial IP addresses with obscure internet service provider (ISP) networks. This lack of centralized cloud mapping makes your automated traffic appear to anti-bot algorithms as genuine user activity.
- Geographic Proximity and Localization: Scraping regional targets requires local network presence. If you are scraping European e-commerce data, executing those requests from a server in a highly secure, privacy-focused data center in the Netherlands or Switzerland can reduce latency and prevent location-based content variation.
- Web scraping’s legality varies. US hosts often suspend servers after legal threats. Offshore hosts at offshorededicatedservers.com typically require judicial review before taking action.
Hardware Architecture: Provisioning Bare Metal for Headless Automation
Web scraping isn’t just network-bound. Hundreds of headless browsers demand substantial compute and memory resources.
1. CPU Core Density: Threading for High Concurrency
Every headless browser instance spawned by an automation framework behaves like a standalone application, requiring dedicated CPU cycles to parse JavaScript, traverse DOM trees, and render page elements.
- The Core Requirement: Avoid shared virtual environments. You need a dedicated, bare-metal server equipped with high-frequency processors, such as the AMD EPYC 24-Core/48-Thread or Dual Intel Xeon configurations.
- An optimized headless Chromium tab uses about 0.5–1 CPU threads. A 48-thread server can run roughly 40–45 active scrapers without major slowdowns.
2. RAM Schedulers: Mitigating Browser Memory Leaks
Headless browsers use lots of memory, and tools like Puppeteer and Playwright may leak memory during long runs.
- The Capacity Target: Do not deploy an automation node with less than 128 GB of DDR5 RAM.
- ECC memory is crucial. It corrects single-bit errors in real time, preventing crashes during 24/7 scraping.
3. High-I/O Storage: Fast Local Caching
Scrapers must write data like raw HTML, screenshots, cookies, and JSON to disk before central processing.
- Use enterprise NVMe SSDs in RAID 1 for fast, reliable disk access during heavy scraping loads.
Advanced Network Topologies for Distributed Extraction
A single server will be limited if all requests use the same IP address. To scale scraping, offshore servers should control a distributed proxy network.
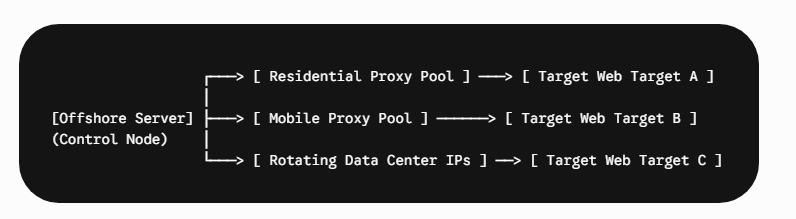
1. Proxy Integration and Internal Rotation
Your offshore core architecture should manage the rotation of multiple proxy types:
- Datacenter IPs: Best for high-speed scraping of targets without aggressive anti-bot setups.
- Residential Proxies: Ideal for navigating sophisticated bot detection networks by routing requests through real home internet connections.
- Mobile Proxies (4G/5G): The cleanest traffic profile available, as anti-bot systems rarely block mobile carrier IPs to avoid locking out legitimate users.
2. Squid or HAProxy Setup on the Control Node
Set up HAProxy or Squid as an internal load balancer to auto-rotate proxies. Scripts connect to one local port; the proxy layer manages rotation.
Hardening and Optimizing the Automation OS Stack
To squeeze every drop of performance out of your offshore dedicated server, you must optimize the base Linux kernel for high-volume network sockets and process management.
1. Adjusting Linux Network Stack Limits
Linux defaults limit concurrent connections and file use. Increase these limits by editing /etc/sysctl.conf:
# Optimize network socket handling for high-concurrency scraping
fs.file-max = 2097152
net.core.somaxconn = 65535
net.ipv4.tcp_max_tw_buckets = 1440000
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.tcp_fin_timeout = 15
net.ipv4.tcp_tw_reuse = 1Run sudo sysctl -p to apply these adjustments instantly.
2. Increasing Process Limits (Ulimits)
* soft nofile 100000
* hard nofile 250000
* soft nproc 100000
* hard nproc 250000When writing your Node.js or Python extraction loops, pass these specific flags to the Chromium initialization method to minimize memory and resource usage:
// Example configuration for Playwright/Puppeteer
const browser = await chromium.launch({
args: [
'--disable-gpu',
'--disable-dev-shm-usage', // Use /tmp instead of shared memory
'--no-sandbox',
'--disable-setuid-sandbox',
'--blink-settings=imagesEnabled=false', // Skip downloading images
'--disable-extensions'
]
});Technical Frequently Asked Questions
Why do anti-bot systems block AWS and GCP so quickly compared to an offshore server?
Anti-bot providers monitor and categorize the entire internet by IP ranges and Autonomous System Numbers (ASNs). Mainstream cloud networks are clearly flagged as hosting corporate traffic rather than real consumers. When an automated script makes requests from an AWS IP address, the target firewall immediately treats it with heightened suspicion.
High-tier offshore servers operate on less-crowded commercial ASNs and offer highly customizable routing options, making it much easier to bypass these automated reputation systems.
What is the ideal offshore location for scraping target sites in North America?
If your primary scraping targets are hosted within North American data centers, you need a balance of legal isolation and low latency. Look for offshore facilities located in Iceland or specific privacy-focused sectors in Western Europe.
These locations provide excellent undersea fiber-optic connectivity to North America keeping round-trip times low while maintaining data-protection standards that insulate your scraping tasks from local corporate complaints.
How much RAM do I need to scrape with 100 concurrent browser windows?
As a rule of thumb, every headless Chromium instance requires between 100 MB and 150 MB of system memory just to initialize, and that can easily climb to 400 MB+ when loading modern, script-heavy web applications. For 100 concurrent running processes, your system must reserve at least 40 GB of RAM solely for the browser overhead.
Combined with your application layer, database caches, and operating system needs, a bare-metal server with 128 GB of RAM is the ideal baseline to avoid performance degradation.
Do offshore servers come with unmetered bandwidth for heavy data mining?
Yes. Many performance tiers available on offshorededicatedservers.com feature true unmetered, high-capacity pipelines (such as dedicated 1 Gbps or 10 Gbps ports). This is a critical advantage over mainstream cloud hosts, which charge high egress fees for every gigabyte of data pulled from their networks.
Unmetered ports let you run high-volume extraction setups 24/7 without worrying about unexpected bandwidth costs.
Can I run a distributed scraping matrix across multiple offshore servers?
Absolutely. The standard enterprise approach involves setting up a cluster of single-tenant offshore machines. You can configure one server as a dedicated Master Node to handle task queues, target parsing, and database storage, while routing the actual extraction tasks out to multiple internal Worker Nodes.
This setup helps isolate your core data storage from the network nodes doing the heavy lifting.
Conclusion: Take Control of Your Extraction Pipelines
Relying on mainstream public cloud infrastructure for large-scale web scraping and data automation is an expensive and unstable strategy. The inevitable IP bans, strict resource limits, and unexpected data egress fees will eventually choke your data pipelines.
By migrating your automation frameworks to dedicated, unmetered offshore servers, you regain control over your data collection infrastructure. Deploying your systems through a secure data center on offshorededicatedservers.com gives you the high core density, flexible network routing, and strong legal protections needed to run high-volume extraction pipelines without interruption. Stop fighting restrictive cloud limitations. Secure your dedicated bare-metal server today and build a data pipeline that scales indefinitely.
Latest Post: